23 Performance
A Shiny app can support thousands or tens of thousands of users, if developed the right way. But most Shiny apps are quickly thrown together to solve a pressing analytic need, and typically begin life with poor performance. This is a feature of Shiny: it allows you to quickly prototype a proof of concept that works for you, before figuring out how to make it fast so many people can use it simultaneously. Fortunately, it’s generally straightforward to get 10-100x performance with a few simple tweaks. This chapter will show you how.
We’ll begin with a metaphor: thinking about a Shiny app like a restaurant. Next, you’ll learn how to benchmark your app, using the shinyloadtest package to simulate many people using your app at the same time. This is the place to start, because it lets you figure you have a problem and helps measure the impact of any changes that you make.
Then you’ll learn how to profile your app using the profvis package to identify slow parts of your R code. Profiling lets you see exactly where your code is spending its time, so you can focus your efforts where they’re most impactful.
Finally, you’ll learn a handful of useful techniques to optimise your code, improving the performance where needed. You’ll learn how to cache reactives, how to move data prep code out of your app, and a little applied psychology to help you app feel as fast as possible.
For a demo of the whole process of benchmarking, profiling, and optimising, I recommend watching Joe Cheng’s rstudio::conf(2019) keynote: Shiny in production: principles, best practices, and tools. In that talk (and accompanying case study), Joe walks through the complete process with a realistic app.
Special thanks to my RStudio colleagues Joe Cheng, Sean Lopp, and Alan Dipert, whose RStudio::conf() talks were particularly helpful when writing this chapter.
23.1 Dining at restaurant Shiny
When considering performance, it’s useful to think of a Shiny app as a restaurant68. Each customer (user) comes into the restaurant (the server) and makes an order (a request), which is then prepared by a chef (the R process). This metaphor is useful because like a restaurant, one R process can serve multiple users at the same time, and there similar ways to dealing with increasing demand.
To begin, you might investigate ways to make your current chef more efficient (optimise your R code). To do so, you’d first spend some time watching your chef work to find the bottlenecks in their method (profiling) and then brainstorming ways to help them work faster (optimising). For example, maybe you could hire a prep cook who can come in before the first customer and chop some vegetables (prepares the data), or you could invest in a time-saving gadget (a faster R package).
Or you might think about adding more chefs (processes) to the restaurant (server). Fortunately, it’s much easier to add more processes69 than hire trained chefs. If you keep hiring more chefs, eventually the kitchen (server) will get too full and you’ll need to add more equipment (memory of cores). Adding more resources allow a server to run more processes is called scaling up70.
At some point, you’ll have crammed as many chefs into your restaurant as you possibly can and it’s still not enough to meet demand. At that point, you’ll need to build more restaurants. This is called scaling out71, and for Shiny it means using multiple servers. Scaling out allows you to handle any number of customers, as long as you can pay the infrastructure costs. I won’t talk more about scaling out in this chapter, because while the details are straightforward, they depend entirely on your deployment infrastructure.
There’s one major place where the metaphor breaks down: a normal chef can make multiple dishes at the same time, carefully interweaving the steps to take advantage of downtime in one recipe to work on another. R, however, is single-threaded, which means that can’t do multiple things at the same time. This is fine if all of the meals are fast to cook, but if someone requests a 24-hour sous vide pork belly, all later customers will have to wait 24 hours before the chef can start on their meal. Fortunately, you can work around this limitation using async programming. Async is a complex topic and beyond the scope of this book, but you can learn more at https://rstudio.github.io/promises/.
23.2 Benchmark
You almost always start by developing an app for yourself: your app is a personal chef who only ever has to serve one customer at a time (you!). While you might be happy with their performance right now, you might also worry that they won’t be able to handle the 10 folks who need to use your app at the same time. Benchmarking lets you check the performance of your app with multiple users, without actually exposing real people to a potentially slow app. Or if you want to serve 100s or 1000s of users, benchmarking will help you figure out just how many users each process can handle, and hence how many servers you’ll need to use.
The benchmarking process is supported by the shinyloadtest package and has three basic steps:
Record a script simulating a typical user with
shinyloadtest::record_session().Replay the script with multiple simultaneous users with the shinycannon command-line tool.
Analyse the results using
shinyloadtest::report().
Here I’ll give an overview of how each of the steps work; if you need more details, check out shinyloadtest’s documentation and vignettes.
23.2.1 Recording
If you’re benchmarking on your laptop, you’ll need to use two different R processes72 — one for Shiny, and one for shinyloadtest.
-
In the first process, start your app and copy the url that it gives you:
runApp("myapp.R") #> Listening on http://127.0.0.1:7716 -
In the second process, paste the url into a
record_session()call:shinyloadtest::record_session("http://127.0.0.1:7716")
record_session() will open a new window containing a version of your app that records everything you do with it.
Now you need to interact with the app to simulate a “typical” user.
I recommend starting with a written script to guide your actions — this will make it easier to repeat in the future, if you discover there’s some important piece missing.
Your benchmarking will only be as good as your simulation, so you’ll need to spend some time thinking about how to simulate a realistic interaction with the app.
For example, don’t forget to add pauses to reflect the thinking time that a real user would need.
Once you’re done, close the app, and shinyloadtest will save recording.log to your working directory.
This records every action in a way that can easily be replayed.
Keep a hold of it as you’ll need it for the next step.
(While benchmarking works great on your laptop, you likely want to simulate the eventual deployment as closely as possible in order to get the most accurate results. So if your company has a special way of serving Shiny apps, talk to your IT folks about setting up an environment that you can use for load testing.)
23.2.2 Replay
Now you have a script that represents the actions of a single user, and we’ll next use it to simulate many people using a special tool called shinycannon. shinycannon is a bit of extra work to install because it’s not an R package. It’s written in Java because the Java language is particularly well suited to the problem of performing tens or hundreds of web requests in parallel, using as few computational resources as possible. This makes it possible for your laptop to both run the app and simulate many users. So start by installing shinycannon, following the instructions at https://rstudio.github.io/shinyloadtest/#shinycannon
Then run shinycannon from the terminal with a command like this:
shinycannon recording.log http://127.0.0.1:7911 \
--workers 10 \
--loaded-duration-minutes 5 \
--output-dir run1There are six arguments to shinycannon:
The first argument is a path to the recording that you created in the previous step.
The second argument is the url to your Shiny app (which you copied and pasted in the previous step).
--workerssets the number of parallel users to simulate. The above command will simulate the performance of your app as if 10 people were using it simultaneously.--loaded-duration-minutesdetermines how long to run the test for. If this is longer than your script takes, shinycannon will start the script again from the beginning.--output-dirgives the name of the directory to save the output. You’re likely to run the load test multiple times as you experiment with performance improvements, so strive to give informative names to these directories.
When load testing for the first time, it’s a good idea to start with a small number of workers and a short duration in order to quickly spot any major problems.
23.2.3 Analysis
Now that you’ve simulated your app with multiple users, it’s time to look at the results.
First, load the data into R using load_runs():
library(shinyloadtest)
df <- load_runs("scaling-testing/run1")This produces a tidy tibble that you can analyse by hand if you want. But typically you’ll create the standard shinyloadtest report. This is an HTML report that contains the graphical summaries that the Shiny team has found to be most useful.
shinyloadtest_report(df, "report.html")I’m not going to discuss all the pages in the report here. Instead I’ll focus on what I think is the most important plot: the session duration. To learn more about the other pages, I highly recommend reading the Analyzing Load Test Logs article.
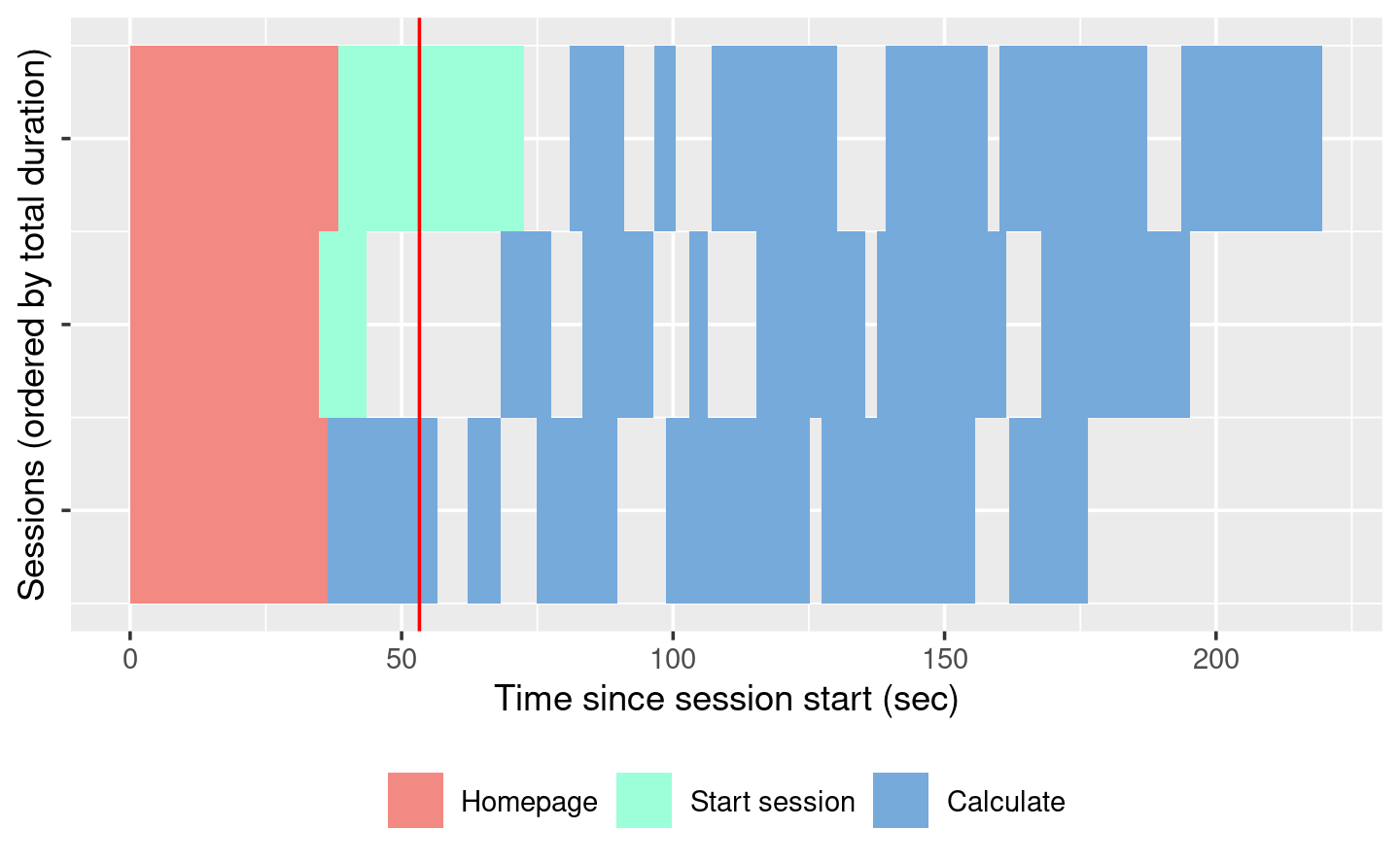
The session duration plot displays each simulated user session as row. Each event is a rectangle with width proportional to time taken, coloured by the event type. The red line shows the time that the original recording took.
When looking at this plot:
Does the app perform equivalently under load as it does for a single user? If so, congratulations! Your app is already fast enough and you can stop reading this chapter 😄.
Is the slowness in the “Homepage”? If so, you’re probably using a
uifunction, and you’re accidentally doing too much work there.Is “Start session” slow? That suggests the execution of your server function is slow. Generally, running the server function should be fast because all you’re doing is defining the reactive graph (which is run in the next step). If it’s slow, move expensive code either outside of
server()(so it’s run once on app startup) or into a reactive (so it’s run on demand).Otherwise, and most typically, the slowness will be in “Calculate”, which indicates that some computation in your reactive is slow, and you’ll need to use the techniques in the rest of the chapter to find and fix the bottlenecks.
23.3 Profiling
If your app is spending a lot of time calculating, you next need to figure out which calculation is slow, i.e. you need to profile your code to find the bottleneck.
We’re going to do profiling with the profvis package, which provides an interactive visualisation of the profiling data collected by utils::Rprof().
I’ll start by introducing the flame graph, the visualisation used for profiling, then show you how to use profvis to profile R code and Shiny apps.
23.3.1 The flame graph
Across programming languages, the most common tool used to visualise profiling data is the flame graph. To help you understand it, I’m going to start by revisiting the basics of code execution, then build up progressively to the final visualisation.
To make the process concrete, we’ll work with following code where I use profvis::pause() (more on that shortly) to indicate work being done:
library(profvis)
f <- function() {
pause(0.2)
g()
h()
10
}
g <- function() {
pause(0.1)
h()
}
h <- function() {
pause(0.3)
}If I asked you to mentally run f() then explain what functions were called, you might say something like this:
- We start with
f(). - Then
f()callsg(), - Then
g()callsh(). - Then
f()callsh().
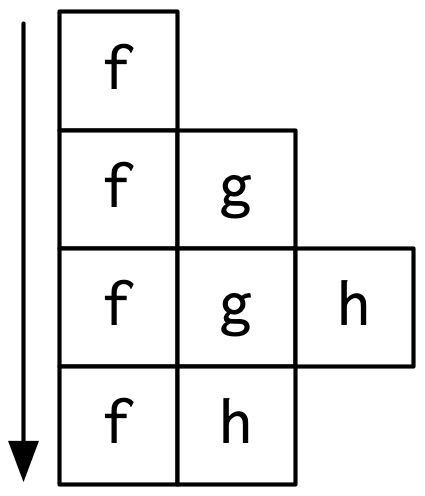
This is a bit hard to follow because we can’t see exactly how the calls are nested, so instead you might adopt a more conceptual description:
- f
- f > g
- f > g > h
- f > h
Here we’ve recorded a list of of call stacks, which you might remember from Section 5.2.1, when we talked about debugging. The call stack is just the complete sequence of calls leading up to a function.
We could convert that list to a diagram by drawing a rectangle around each function name:
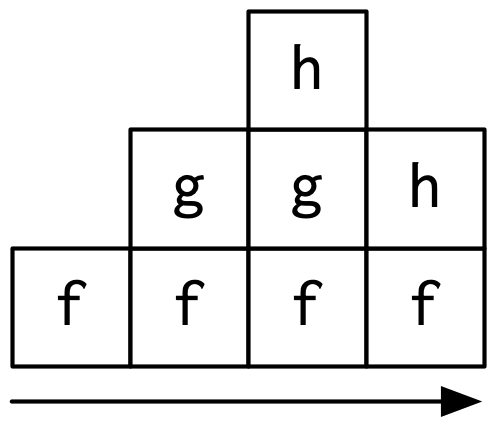
I think it’s most natural to think about time flowing downwards, from top-to-bottom, in the same way you usually think about code running. But by convention, flame graphs are drawn with time flowing from left-to-right, so we rotate our diagram by 90 degrees:
We can make this diagram more informative by making the width of each call proportional to the amount of time it takes. I also added some grid lines in the background to make it easier to check my work:
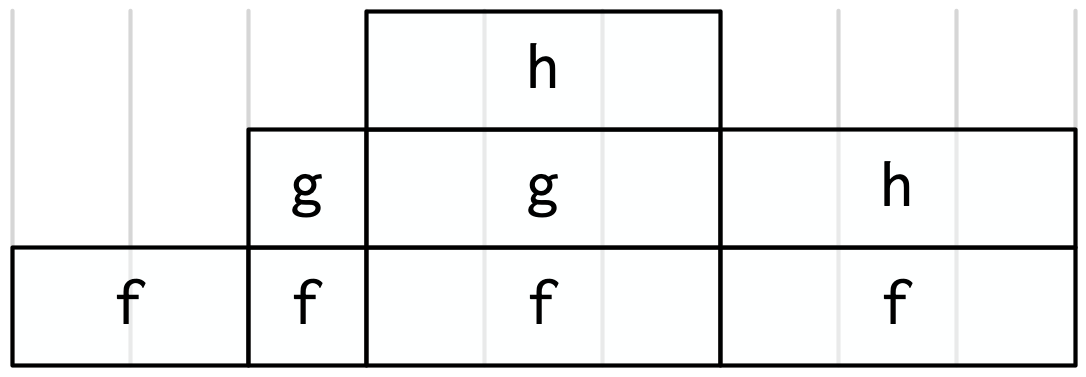
Finally, we can clean it up a little by combining adjacent calls to the same function:
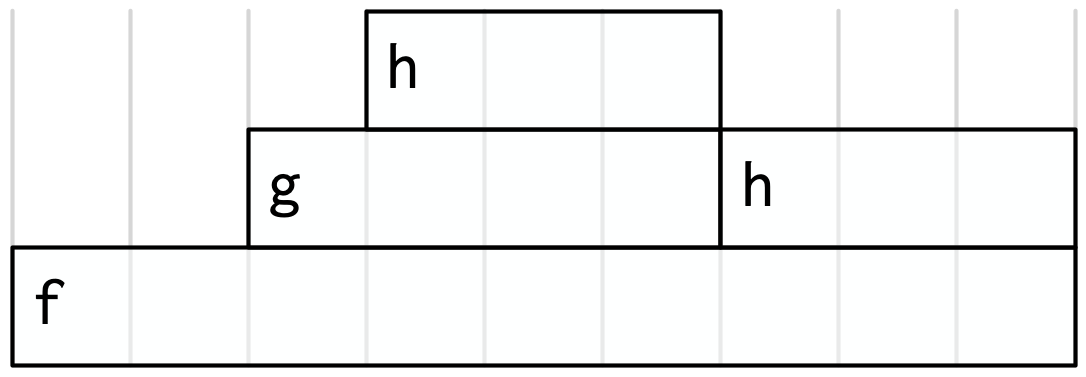
This is a flame graph!
It’s easy to see both how long f() takes to run, and why it takes that long, i.e. where its time is spend.
You might wonder why it’s called a flame graph. Most flame graphs in the wild are randomly coloured with “warm” colours, meant evoke the idea of the computer running “hot”. However, since those colours don’t add any additional information, we usually omit them and stick to black and white. You can learn more about this colour scheme, alternatives, and the history of flame graphs in “The Flame Graph73”.
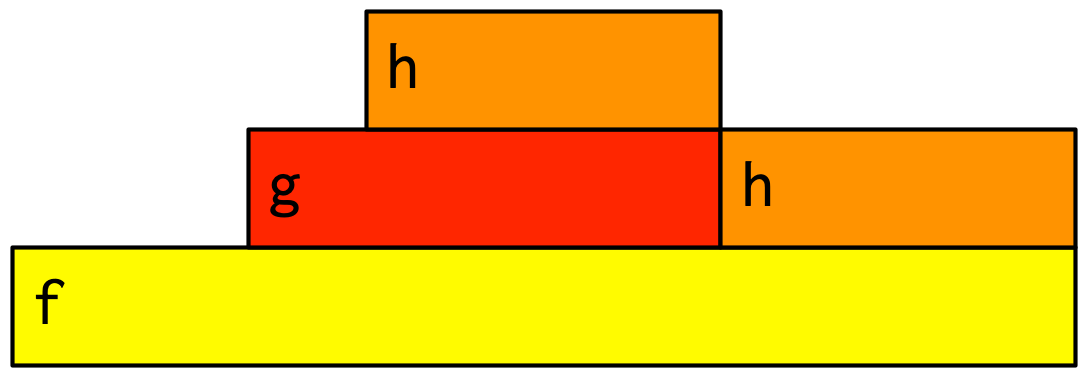
23.3.2 Profiling R code
Now you understand the flame graph, let’s apply it to real code with the profvis package.
It’s easy to use: just wrap the code you want to profile in profvis::profvis():
profvis::profvis(f())After the code has completed, profvis will pop up an interactive visualisation, Figure 23.1. You’ll notice that it looks very similar to the graphs that I drew by hand, but the timings aren’t exactly the same. That’s because R’s profiler works by stopping execution every 10ms and recording the call stack. Unfortunately, we can’t always stop at exactly the we want because R might be in the middle of something that can’t be interrupted. This means that the results are subject to a small amount of random variation; if you re-profiled this code, you’d get another slightly different result.

Figure 23.1: Results of profiling f() with profvis. X-axis shows elapsed time in ms, y-axis shows depth of call stack.
As well as a flame graph, profvis also does its best to find and display the underlying source code so that you can click on a function in the flame graph to see exactly what’s run.
23.3.3 Profiling a Shiny app
Not much changes when profiling a Shiny app.
To see the difference, I’ll make a very simple app that wraps around f().
The results are shown in Figure 23.2.
ui <- fluidPage(
actionButton("x", "Push me"),
textOutput("y")
)
server <- function(input, output, session) {
output$y <- eventReactive(input$x, f())
}
# Note the explicit call to runApp() here: this is important
# as otherwise the app won't actually run.
profvis::profvis(runApp(shinyApp(ui, server)))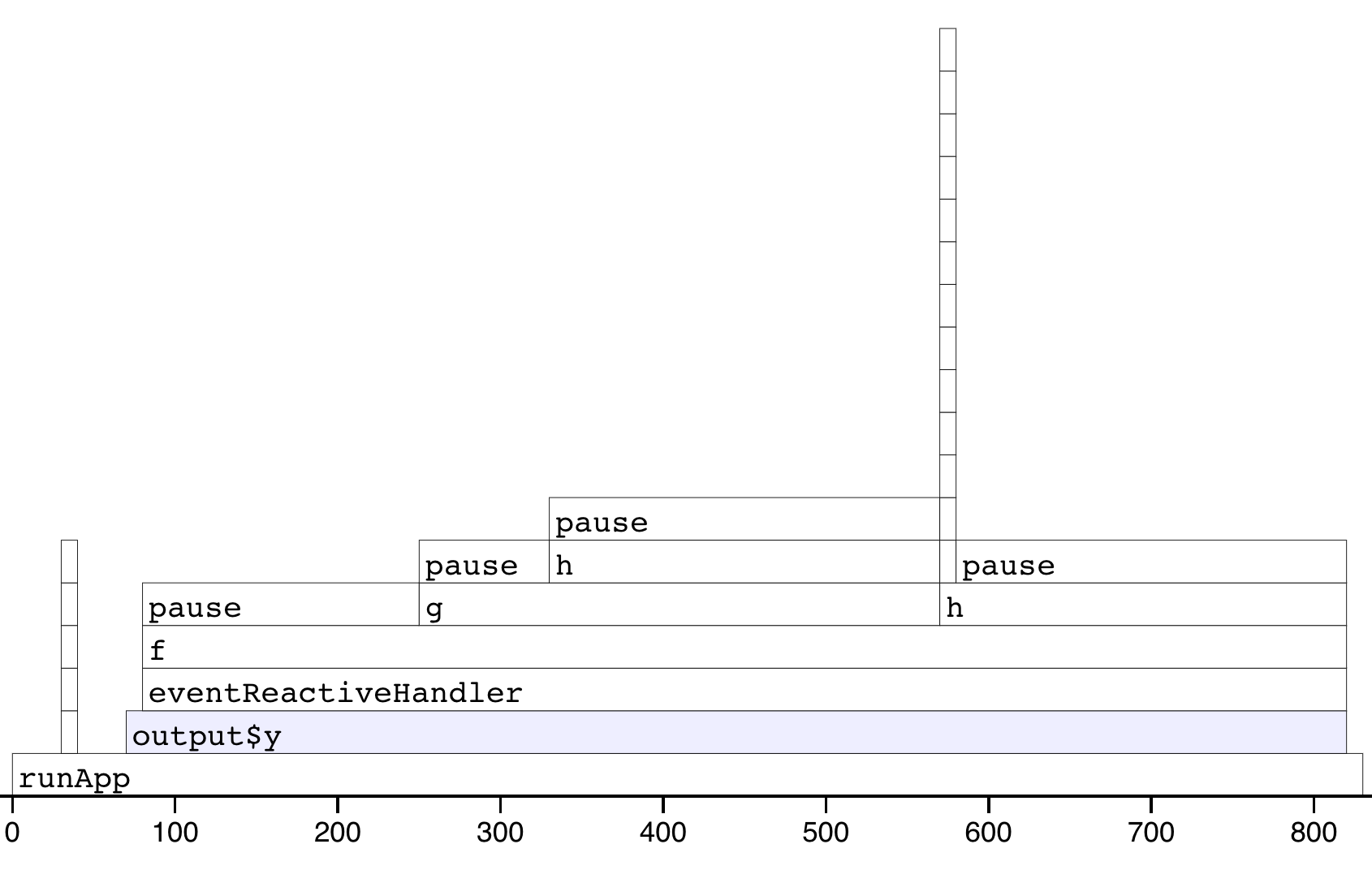
Figure 23.2: Results of profiling a Shiny app that uses f(). Note that the call stack is deeper and we have a couple of tall towers.
The output looks very similar to the last run. There are a couple of differences:
f()is no longer at the bottom of the call stack. Instead it is called byeventReactiveHandler()(the internal function that powerseventReactive()), which is triggered byoutput$y, which is wrapped insiderunApp().There are two very tall towers. Generally, these can be ignored because they don’t take up much time and will vary from run to run, because of the stochastic nature of the sampler. If you do want to learn more about them, you can hover to find out the function calls. In this case the short tower on the left is the setup of the
eventReactive()call, and the tall tower on the right is R’s byte code compiler being triggered.
For more details, I recommend the profvis documentation, particular it’s FAQs.
23.3.4 Limitations
The most important limitation of profiling is due to the way it works: R has to stop the process and inspect what R functions are currently run. That means that R has to be in control. There are a few places where this doesn’t happen:
Certain C functions that don’t regularly check for user interrupts. These are the same C functions you can’t use Escape/Ctrl + C to stop run. That’s generally not a good programming practice, but they do exist in the wild.
Sys.sleep()asks the operating system to “park” the process for some amount of time, so R is not actually running. This is why we had to useprofvis::pause()above.Downloading data from the internet is usually done in a different process, so won’t be tracked by R.
23.4 Improve performance
The most efficient way to improve performance is to find the slowest thing in the profile, and try to speed it up. Once you’ve isolated a slow part, make sure it’s in a stand alone function (Chapter 18). Then make a minimal snippet of code that recreates the slowness, re-profiling it to check that you captured it correctly. You’ll re-run this snippet multiple time as you try out possible improvements. I also recommend writing a few tests (Chapter 21) because in my experience the easiest way to make code faster is to make it incorrect 😆.
Shiny code is just R code, so most techniques for improving performance are general. Two good places to start are the Improving performance section of Advanced R and Efficient R programming by Colin Gillespie and Robin Lovelace. I’m not going to repeat their advice here: instead, I’ll focus on the techniques that are most likely to affect your Shiny app. I also highly recommend Alan Dipert’s rstudio::conf(2018) talk: Making Shiny fast by doing as little as possible.
Begin by resolving any issues where existing code is run more often than you expect — make sure you’re not repeating the same work in multiple reactives and that the reactive graph isn’t updating more often than you expect (Section 14.6).
Next, I’ll discuss the easiest way to improve the performance of your app, using caching to remember and replay slow calculations. I’ll finish up with two other techniques that can help many Shiny apps: pulling out expensive preprocessing into a separate step and carefully managing user expectations
23.5 Caching
Caching is a very powerful technique for improving code performance. The basic idea is to record the inputs to and outputs from every call to a function. When the cache function is called with a set of inputs that it’s already seen, it can replay the recorded output without recomputing. Packages like memoise provide tools for caching regular R functions.
Caching is particularly effective for Shiny apps, because the cache can be shared across users. That means when many people are using the same app, only the first user needs to wait for the results to be computed, then everyone else gets a speedy result from the cache.
Shiny provides a general tool for caching any reactive expression or render function: bindCache()74.
As you know, reactive expressions already cache the most recently computed value; bindCache() allows you to cache any number of values and to share those values across users.
In this section, I’ll introduce you to the basics of bindCache(), show you a couple of practical examples, and then talk through some of the details of the cache “key” and scope.
If you want to learn more, I recommend starting with “Using caching in Shiny to maximise performance” and “Using bindCache() to speed up an app”.
23.5.1 Basics
bindCache() is easy to use.
Simply pipe either the reactive() or render* function that you want to cache into bindCache():
r <- reactive(slow_function(input$x, input$y)) %>%
bindCache(input$x, input$y)
output$text <- renderText(slow_function2(input$z)) %>%
bindCache(input$z)The additional arguments are are the cache keys — these are the values that are used to determine if a computation has been seen before. We’ll discuss the cache keys in more details after showing a couple of practical uses.
23.5.2 Caching a reactive
A common place to use caching is in conjunction with an web API — even if the API is very quick, you still have to send the request, wait for the server to respond, and then parse the result. So caching API results often yield a big performance improvement. Let’s illustrate that with a simple example using the gh package that talks to GitHub’s API.
Imagine you want to design app that shows what people have been working on lately. Here I’ve written a little function that gets the data from Github’s event API and does some simple rectangling to turn it into a tibble:
library(purrr)
latest_events <- function(username) {
json <- gh::gh("/users/{username}/events/public", username = username)
tibble::tibble(
repo = json %>% map_chr(c("repo", "name")),
type = json %>% map_chr("type"),
)
}
system.time(hadley <- latest_events("hadley"))
#> user system elapsed
#> 0.065 0.005 0.442
head(hadley)
#> # A tibble: 6 × 2
#> repo type
#> <chr> <chr>
#> 1 posit-dev/open-source-website PullRequestReviewEvent
#> 2 r-lib/carrier PullRequestReviewEvent
#> 3 r-lib/carrier PullRequestReviewEvent
#> 4 r-lib/carrier PullRequestReviewCommentEvent
#> 5 r-lib/carrier PullRequestReviewCommentEvent
#> 6 r-lib/carrier PullRequestReviewEventAnd I can turn that into a very simple app:
ui <- fluidPage(
textInput("username", "GitHub user name"),
tableOutput("events")
)
server <- function(input, output, session) {
events <- reactive({
req(input$username)
latest_events(input$username)
})
output$events <- renderTable(events())
}This app is going to feel a little sluggish because every time you type in a username, it’s going to have to re-request the data, even if you just asked for it 15 seconds ago.
We can dramatically improve performance by using bindCache():
server <- function(input, output, session) {
events <- reactive({
req(input$username)
latest_events(input$username)
}) %>% bindCache(input$username)
output$events <- renderTable(events())
}You might have spotted a problem with this approach — what happens if you come back to it tomorrow and request data for the same user?
You’ll get today’s data, even though there might have been new activity.
There’s an implicit dependency on time that you need to make explicit.
You can do that by adding Sys.Date() to the cache key, so that the cache effectively only lasts for a single day:
server <- function(input, output, session) {
events <- reactive({
req(input$username)
latest_events(input$username)
}) %>% bindCache(input$username, Sys.Date())
output$events <- renderTable(events())
}You might worry that the cache will steadily accumulate data from past days that you’ll never look at again, but fortunately the cache has a fixed total size, and is smart enough to automatically remove the least recently used data when it needs more space.
23.5.3 Caching plots
Most of the time you’ll cache reactives, but you can also use bindCache() with render functions.
Most render functions are pretty speedy, but there’s one that can be slow if you have complex graphics: renderPlot().
For example, take the following app. If you run it yourself, you’ll notice the first time you show each plot, it takes a noticeable fraction of a second to render because it has to draw ~50,000 points. But the next time you draw each plot, it appears instantly because it’s retrieved from the cache.
library(ggplot2)
ui <- fluidPage(
selectInput("x", "X", choices = names(diamonds), selected = "carat"),
selectInput("y", "Y", choices = names(diamonds), selected = "price"),
plotOutput("diamonds")
)
server <- function(input, output, session) {
output$diamonds <- renderPlot({
ggplot(diamonds, aes(.data[[input$x]], .data[[input$y]])) +
geom_point()
}) %>% bindCache(input$x, input$y)
}(If the .data syntax is unfamiliar to you, see Chapter 12 for details.)
There’s one special consideration when it comes to caching plots: each plot is drawn in a variety of sizes, because the default plot occupies 100% of the available width, which varies as you resize the browser.
That flexibility doesn’t work very well for caching, because even a single pixel difference in the size would mean that the plot couldn’t be retrieved from the cache.
To avoid this problem, bindCache() caches plots with fixed sizes.
The defaults are carefully chosen to “just work” in most cases, but if needed you can control with the sizePolicy argument, and learn more in the ?sizeGrowthRatio.
23.5.4 Cache key
It’s worth talking briefly about the cache key: the set of values used to figure out whether or not the computation has been previously performed.
These values are also used to determine the reactive dependencies, much like the first argument of observeEvent() or eventReactive().
That means if you use the wrong cache key you can get very confusing results.
For example, image that I have this cached reactive:
If input$y changes, r() will not recompute.
And if the result is retrieved from the cache, it will be the sum of the current value of x and whatever value y happened to have when the value was cached.
So the cache key should always include all of the reactive inputs in the expression. But you may also want to include additional values that are not used in the reactive. The most useful example of this is adding the current day, or some rounded current time, so that cached values are only used for a fixed amount of time.
As well as inputs, you can use other reactive()s as cache keys, but you’ll need to keep them as simple as possible (i.e. atomic vectors, or simple lists of atomic vectors).
Don’t use large datasets because it is expensive to figure out if a large data frame has already been seen, and that will reduce the benefit you see from caching.
23.5.5 Cache scope
By default, the plot cache is stored in memory, is never bigger than 200 MB, is shared across all users a single process, and is lost when the app restarts. You can change this default for individual reactives or for the whole session:
bindCache(…, cache = "session")will use a separate cache for each user sessions. This ensures that private data is not potentially shared between users, but it also reduces the benefit of caching.Use
shinyOptions(cache = cachem::cache_mem())orshinyOptions(cache = cachem::cache_disk())to change the default cache across the whole app. You can use to make a cache is shared across multiple processes and lasts across app restarts. See?bindCachefor more details.
It’s also possible to chain multiple caches together or write your own custom storage backend.
You can learn more about these options in the documentation for cachem, the caching package that powers bindCache().
23.6 Other optimisations
There are two other optimisations that crop up in many apps: performing data import and manipulation on a schedule, and carefully managing user expectations.
23.6.1 Schedule data munging
Imagine that your Shiny app uses a dataset which requires a little initial data cleaning. The data prep is relatively complicated and takes a non-trivial amount of time. You’ve discovered that it’s a bottleneck for your app and want to do better.
Let’s pretend that you’ve already extracted the code out into a function, and it looks something like this:
my_data_prep <- function() {
df <- read.csv("path/to/file.csv")
df %>%
filter(!not_important) %>%
group_by(my_variable) %>%
some_slow_function()
}And currently you call it in your server function:
server <- function(input, output, session) {
df <- my_data_prep()
# Lots more code
}The server function is called every time a new session starts, but the data is always the same, so you can immediately make your app faster (and use less memory) by moving the data processing out of server():
df <- my_data_prep()
server <- function(input, output, session) {
# Lots more code
}Since you’re paying attention to this code, it’s also worth checking that you’re using the most efficient way to load your data:
If you have a flat file, try
data.table::fread()orvroom::vroom()instead ofread.csv()orread.table().If you have a data frame, try saving with
arrow::write_feather()and reading witharrow::read_feather(). Feather is a binary file format that can be considerably faster75 to read and write.If you have objects that aren’t data frames, try using
qs::qread()/qs::qsave()instead ofreadRDS()/saveRDS().
If these changes aren’t enough to resolve the bottleneck you might consider using a separate cron job or scheduled RMarkdown report to call my_data_prep() and save the results.
Then your app can load the pre-prepared data and get to work.
This is like hiring a prep chef who comes in at 3am (when there are no customers) so that during the lunch rush your chefs can be as efficient as possible.
23.6.2 Manage user expectations
Finally, there a few tweaks you can make to your app design to make it feel faster, and improve the overall user experience of your app. Here are four tips that can be used in many apps:
Split your app up into tabs, using
tabsetPanel(). Only outputs on the current tab are recomputed, so you can use this to focus computation on what the user is currently looking at.Require a button press to start a long-running operation. Once the operation starts, let the user know what’s happening using the techniques of Section 8.2. If possible, display an incremental progress bar (Section 8.3) because there’s good evidence that progress bars make operations feel faster: <https://www.nngroup.com/articles/progress-indicators/>.
If the app requires significant work to happen on startup (and you can’t reduce it with preprocessing), make sure to design your app so that the UI can still appear, so that you can let the user know that they’ll need to wait.
Finally, if you want to keep the app responsive while some expensive operation happens in the background, it’s time to learn about async programming: <https://rstudio.github.io/promises>.
23.7 Summary
This chapter has given you the tools to precise measure and improve the performance of any shiny app. You learned about shinyloadtest to measure the performance, using shinycannon to simulate multiple users working with your app at the same time. Then you learned how to use profvis to find the single most expensive operation, and a grab-bag of techniques that you can use to improve it.
This is the last chapter in Mastering Shiny — thank your for making it all the way to the end! I hope you have found the book useful, and that the skills I have given you help you produce many compelling Shiny apps. I’d love to hear if you’ve found the book useful, or if there’s anything that you think could be improved in the future. The best way to get in touch is twitter, @hadleywickham, or Github, https://github.com/hadley/mastering-shiny/. Thanks again for reading, and best wishes for your future Shiny apps!